English
English
NVIDIA A30 GPU Tensor Core
Wszechstronne przyspieszenie obliczeń dla serwerów korporacyjnych głównego nurtu.
Wszechstronne przyspieszenie obliczeń dla serwerów korporacyjnych głównego nurtu.
Przyspiesz wydajność każdego obciążenia w przedsiębiorstwie dzięki GPU Tensor Core NVIDIA A30. Dzięki rdzeniom Tensor w architekturze NVIDIA Ampere i technologii Multi-Instance GPU (MIG) A30 zapewnia przyspieszenia w sposób bezpieczny w różnych obciążeniach, w tym wnioskowania AI na dużą skalę oraz aplikacji obliczeń o wysokiej wydajności (HPC). Łącząc szybką przepustowość pamięci i niskie zużycie energii w formacie PCIe — optymalnym dla serwerów głównego nurtu — A30 umożliwia utworzenie elastycznego centrum danych i dostarcza maksymalną wartość dla przedsiębiorstw.
Architektura NVIDIA Ampere jest częścią zintegrowanej platformy NVIDIA EGX™, która łączy elementy sprzętowe, sieciowe, oprogramowanie, biblioteki oraz zoptymalizowane modele i aplikacje AI z katalogu NVIDIA NGC™. Stanowiąc najsilniejszą platformę end-to-end AI i HPC dla centrów danych, umożliwia badaczom szybkie dostarczanie rezultatów w rzeczywistych warunkach i wdrażanie rozwiązań na dużą skalę.
Pre-trening BERT Large (normalizowany)

ERT-Large Pre-Training (9/10 epochs) Phase 1 and (1/10 epochs) Phase 2, Sequence Length for Phase 1 = 128 and Phase 2 = 512, dataset = real, NGC™ container = 21.03,
8x GPU: T4 (FP32, BS=8, 2) | V100 PCIE 16GB (FP32, BS=8, 2) | A30 (TF32, BS=8, 2) | A100 PCIE 40GB (TF32, BS=54, 8) | batch sizes indicated are for Phase 1 and Phase 2 respectively
Szkolenie modeli AI dla wyzwań nowej generacji, takich jak AI konwersacyjna, wymaga ogromnej mocy obliczeniowej i skalowalności.
Rdzenie Tensor NVIDIA A30 z precyzją Tensor Float (TF32) zapewniają do 10 razy wyższą wydajność w porównaniu do NVIDIA T4 bez żadnych zmian w kodzie oraz dodatkowy wzrost o 2 razy dzięki automatycznej mieszanej precyzji i FP16, co daje łączny wzrost przepustowości o 20 razy. W połączeniu z NVIDIA® NVLink®, PCIe Gen4, siecią NVIDIA oraz NVIDIA Magnum IO™ SDK, możliwe jest skalowanie do tysięcy GPU.
Rdzenie Tensor i MIG umożliwiają dynamiczne wykorzystanie A30 w obciążeniach przez cały dzień. Może być wykorzystywany do wnioskowania produkcyjnego w szczytowym zapotrzebowaniu, a część GPU może być ponownie użyta do szybkiego ponownego trenowania tych samych modeli w godzinach poza szczytem.
NVIDIA ustanowiła wiele rekordów wydajności w MLPerf, ogólnoprzemysłowym benchmarku dla treningu AI.
Dowiedz się więcej o architekturze NVIDIA Ampere do treningu.
A30 wykorzystuje przełomowe funkcje do optymalizacji obciążeń wnioskowania. Przyspiesza pełen zakres precyzji, od FP64 do TF32 i INT4. Obsługując do czterech MIGów na GPU, A30 umożliwia jednoczesne działanie wielu sieci w zabezpieczonych partycjach sprzętowych z zagwarantowaną jakością usług (QoS). Dodatkowo, wsparcie dla rzadkości strukturalnej przynosi do 2 razy większą wydajność na wierzchu już uzyskanych zysków wydajności wnioskowania A30.
Wiodąca na rynku wydajność AI NVIDII została zaprezentowana w MLPerf Inference. W połączeniu z serwerem wnioskowania NVIDIA Triton™, który z łatwością wdraża AI na dużą skalę, A30 przynosi tę przełomową wydajność do każdego przedsiębiorstwa.
Wnioskowanie BERT Large (normalizowane)
Przepustowość dla opóźnienia <10 ms.

NVIDIA® TensorRT®, Precision = INT8, Sequence Length = 384, NGC Container 20.12, Latency <10ms, Dataset = Synthetic 1x GPU: A100 PCIe 40GB (BS=8) | A30 (BS=4) | V100 SXM2 16GB (BS=1) | T4 (BS=1)
Wnioskowanie RN50 v1.5 (normalizowane)
Przepustowość dla opóźnienia <7 ms.

TensorRT, NGC Container 20.12, Latency <7ms, Dataset=Synthetic, 1x GPU: T4 (BS=31, INT8) | V100 (BS=43, Mixed precision) | A30 (BS=96, INT8) | A100 (BS=174, INT8)
LAMMPS (normalizowane)

Dataset: ReaxFF/C, FP64 | 4x GPU: T4, V100 PCIE 16GB, A30
Aby odkryć nową generację odkryć, naukowcy wykorzystują symulacje, aby lepiej zrozumieć otaczający nas świat.
NVIDIA A30 wyposażona jest w rdzenie Tensor FP64 architektury NVIDIA Ampere, które oferują największy skok w wydajności HPC od momentu wprowadzenia GPU. W połączeniu z 24 gigabajtami (GB) pamięci GPU o przepustowości 933 gigabajtów na sekundę (GB/s), badacze mogą szybko rozwiązywać obliczenia o podwójnej precyzji. Aplikacje HPC mogą również wykorzystywać TF32, aby osiągać wyższą przepustowość dla operacji mnożenia macierzy o pojedynczej precyzji.
Kombinacja rdzeni Tensor FP64 i MIG umożliwia instytucjom badawczym bezpieczne podział GPU, pozwalając wielu badaczom na dostęp do zasobów obliczeniowych z gwarantowaną jakością usług (QoS) i maksymalnym wykorzystaniem GPU. Przedsiębiorstwa wdrażające AI mogą korzystać z możliwości wnioskowania A30 podczas szczytowych okresów zapotrzebowania, a następnie ponownie wykorzystać te same serwery obliczeniowe do obciążeń HPC i treningu AI w godzinach poza szczytem.
Sprawdź Najnowszą Wydajność GPU w Aplikacjach HPC

Procesor graficzny NVIDIA A30 jest specjalnie zoptymalizowany pod kątem głębokiego uczenia się, zaspokajając wymagające potrzeby obliczeniowe wdrożeń sztucznej inteligencji w centrach danych. Zbudowany w oparciu o wydajną architekturę Ampere, A30 jest wyposażony w dużą liczbę rdzeni CUDA i rdzeni Tensor, umożliwiając przetwarzanie sieci neuronowych z wyjątkową szybkością i dokładnością. Ten procesor graficzny doskonale radzi sobie z obciążeniami wnioskowania na dużą skalę w różnych branżach, od przetwarzania języka naturalnego i rozpoznawania obrazów po systemy rekomendacji i pojazdy autonomiczne. Obsługa obliczeń o mieszanej precyzji przez A30 zwiększa wydajność, równoważąc dokładność obliczeń z wydajnością, zapewniając szybkie wyniki wnioskowania bez uszczerbku dla precyzji modelu. Integracja z zestawem narzędzi do optymalizacji wnioskowania TensorRT firmy NVIDIA jeszcze bardziej usprawnia wdrażanie i maksymalizuje przepustowość, ułatwiając przedsiębiorstwom efektywne skalowanie aplikacji AI. Ogólnie rzecz biorąc, procesor graficzny NVIDIA A30 to solidne rozwiązanie dla przedsiębiorstw, które chcą przyspieszyć swoje możliwości wnioskowania w zakresie głębokiego uczenia się, zapewniając doskonałą wydajność i skalowalność w środowiskach opartych na sztucznej inteligencji.
Procesor graficzny NVIDIA A30 ma zrewolucjonizować wysokowydajną analizę danych dzięki swoim solidnym możliwościom i wydajnej architekturze Ampere. Dostosowany do wymagających aplikacji wymagających dużej ilości danych, A30 jest wyposażony w bogactwo rdzeni CUDA i rdzeni Tensor, które wyróżniają się przyspieszaniem złożonych zadań analitycznych, takich jak przetwarzanie danych na dużą skalę, uczenie maszynowe i analityka predykcyjna. Duża przepustowość pamięci i obsługa technologii NVIDIA NVLink zapewniają szybki dostęp do ogromnych zbiorów danych i ich przetwarzanie, umożliwiając organizacjom szybkie uzyskiwanie informacji i podejmowanie świadomych decyzji. Wszechstronność A30 obejmuje obsługę obliczeń o mieszanej precyzji, optymalizując wydajność obliczeniową bez utraty dokładności, która jest kluczowa dla wydajnej obsługi różnorodnych obciążeń. Zintegrowany z pakietem narzędzi programowych NVIDIA, takimi jak RAPIDS do przyspieszanych przez procesor graficzny procesów analizy danych i bibliotekami CUDA-X, A30 upraszcza wdrażanie i skalowanie rozwiązań do analizy danych w chmurze hybrydowej i środowiskach lokalnych. Ostatecznie procesor graficzny NVIDIA A30 ustanawia nowy standard w zakresie wysokowydajnej analizy danych, umożliwiając przedsiębiorstwom wydobywanie przydatnych wniosków szybciej i skuteczniej niż kiedykolwiek wcześniej.


Procesor graficzny NVIDIA A30 stanowi znaczący postęp w dziedzinie obliczeń o dużej wydajności (HPC), zaprojektowanych w celu zapewnienia niezrównanej mocy obliczeniowej i wydajności w szerokim zakresie zadań obliczeniowych. Zbudowany w oparciu o wydajną architekturę Ampere, A30 zawiera znaczną liczbę rdzeni CUDA i rdzeni Tensor, zoptymalizowanych do obsługi złożonych symulacji naukowych, analiz numerycznych i obliczeń wymagających dużej ilości danych z niezwykłą szybkością i dokładnością. Wysoka przepustowość pamięci i obsługa technologii NVIDIA NVLink umożliwiają bezproblemową komunikację pomiędzy procesorami graficznymi i innymi komponentami systemu, zwiększając ogólną wydajność i skalowalność systemu. Solidne możliwości obliczeniowe A30 sprawiają, że idealnie nadaje się do przyspieszania aplikacji w takich dziedzinach, jak fizyka, chemia, prognozowanie pogody i dynamika molekularna, gdzie krytyczne znaczenie ma szybkie przetwarzanie danych i symulacja. Integracja z platformą obliczeń równoległych i bibliotekami CUDA firmy NVIDIA zapewnia kompatybilność i ułatwia opracowywanie zoptymalizowanych rozwiązań programowych, umożliwiając badaczom i inżynierom skuteczne radzenie sobie z większymi i bardziej złożonymi problemami. Podsumowując, procesor graficzny NVIDIA A30 to potężne rozwiązanie dla środowisk HPC, oferujące niezrównaną wydajność i niezawodność w celu napędzania innowacji i odkryć naukowych.
Procesor graficzny NVIDIA A10 to wszechstronna jednostka mocy zaprojektowana z myślą o podniesieniu poziomu głównego nurtu obliczeń korporacyjnych, zapewniając niezrównaną wydajność przy różnorodnych obciążeniach. Wykorzystując zaawansowaną architekturę Ampere, A10 zapewnia znaczną poprawę wydajności obliczeniowej, dzięki czemu idealnie nadaje się do analizy danych, infrastruktury wirtualnych pulpitów (VDI) i środowisk przetwarzania w chmurze. Bogate rdzenie CUDA i rdzenie Tensor umożliwiają przyspieszone przetwarzanie złożonych obliczeń, ułatwiając szybsze wyciąganie wniosków z dużych zbiorów danych i zwiększając wydajność modelu uczenia maszynowego. Szeroka przepustowość pamięci A10 zapewnia płynne zarządzanie zadaniami wymagającymi dużej ilości danych, podczas gdy technologia wirtualizacji NVIDIA umożliwia wielu użytkownikom jednoczesny dostęp do możliwości procesora graficznego, optymalizując wykorzystanie zasobów i redukując koszty operacyjne. Co więcej, płynna integracja A10 z kompleksowym ekosystemem oprogramowania NVIDIA, w tym CUDA, cuDNN i TensorRT, zapewnia kompatybilność i łatwość wdrożenia w istniejącej infrastrukturze IT. Cechy te wspólnie pozycjonują NVIDIA A10 jako kluczowy atut dla przedsiębiorstw, których celem jest zwiększenie mocy obliczeniowej, usprawnienie operacji i stymulowanie innowacji.

Naukowcy zajmujący się danymi muszą mieć możliwość analizy, wizualizacji i przekształcania ogromnych zestawów danych w wartościowe wnioski. Jednak rozwiązania skalowalne często napotykają problemy z danymi rozproszonymi na wielu serwerach.
Przyspieszone serwery z A30 oferują niezbędną moc obliczeniową — w połączeniu z dużą pamięcią HBM2, przepustowością pamięci wynoszącą 933 GB/s oraz skalowalnością dzięki NVLink — do obsługi tych obciążeń. W połączeniu z NVIDIA InfiniBand, NVIDIA Magnum IO oraz pakietem otwartych bibliotek RAPIDS™, w tym RAPIDS Accelerator dla Apache Spark, platforma centrum danych NVIDIA przyspiesza te ogromne obciążenia na niespotykanie wysokich poziomach wydajności i efektywności.


A30 z MIG maksymalizuje wykorzystanie infrastruktury przyspieszonej przez GPU.
A30 z MIG maksymalizuje wykorzystanie infrastruktury przyspieszonej przez GPU. Dzięki MIG, GPU A30 może być podzielone na maksymalnie cztery niezależne instancje, co pozwala wielu użytkownikom na dostęp do przyspieszenia GPU.
MIG współpracuje z Kubernetes, kontenerami oraz wirtualizacją serwera opartą na hypervisorach. MIG umożliwia menedżerom infrastruktury oferowanie odpowiednio dopasowanego GPU z gwarantowaną jakością usług (QoS) dla każdego zadania, rozszerzając dostęp do zasobów obliczeń przyspieszonych dla każdego użytkownika.

NVIDIA AI Enterprise, kompleksowy zestaw oprogramowania natywnego w chmurze do AI i analizy danych, jest certyfikowany do działania na A30 w wirtualnej infrastrukturze opartej na hypervisorach z VMware vSphere. To umożliwia zarządzanie i skalowanie obciążeń AI w hybrydowym środowisku chmurowym.

Systemy Certyfikowane przez NVIDIĘ™ z GPU NVIDIA A30 łączą przyspieszenie obliczeniowe oraz szybką, bezpieczną sieć NVIDIA w serwerach centrów danych przedsiębiorstw, zbudowanych i sprzedawanych przez partnerów OEM NVIDIĘ. Program ten umożliwia klientom identyfikację, nabywanie i wdrażanie systemów do tradycyjnych oraz różnorodnych nowoczesnych aplikacji AI z katalogu NVIDIA NGC na jednej wysokowydajnej, opłacalnej i skalowalnej infrastrukturze.
| FP64 | 5.2 teraFLOPS | |
| FP64 Tensor Core | 10.3 teraFLOPS | |
| FP32 | 10.3 teraFLOPS | |
| TF32 Tensor Core | 82 teraFLOPS | 165 teraFLOPS* | |
| BFLOAT16 Tensor Core | 165 teraFLOPS | 330 teraFLOPS* | |
| FP16 Tensor Core | 165 teraFLOPS | 330 teraFLOPS* | |
| INT8 Tensor Core | 330 TOPS | 661 TOPS* | |
| INT4 Tensor Core | 661 TOPS | 1321 TOPS* | |
| Media engines | 1 optical flow accelerator (OFA) 1 JPEG decoder (NVJPEG) 4 video decoders (NVDEC) |
|
| GPU memory | 24GB HBM2 | |
| GPU memory bandwidth | 933GB/s | |
| Interconnect | PCIe Gen4: 64GB/s Third-gen NVLINK: 200GB/s** |
|
| Form factor | Dual-slot, full-height, full-length (FHFL) | |
| Max thermal design power (TDP) | 165W | |
| Multi-Instance GPU (MIG) | 4 GPU instances @ 6GB each 2 GPU instances @ 12GB each 1 GPU instance @ 24GB |
|
| Virtual GPU (vGPU) software support | NVIDIA AI Enterprise NVIDIA Virtual Compute Server |
|
* Z rzadkością
** Most NVLink dla maksymalnie dwóch GPU

 TŁO
TŁOWartość marki i satysfakcja klienta budowane są nie tylko poprzez jakość i funkcje produktu, ale także poprzez spełnianie oczekiwań klienta. Ponieważ klienci w Japonii mają szczególnie wysokie oczekiwania co do jakości, należy ustanowić system zdolny do odpowiadania na ten poziom zapotrzebowania. Jednak zwiększenie konkurencyjności kosztowej wymaga, aby jakość była utrzymywana jednocześnie z dostosowywaniem procedur i świadczeniem szybkich usług.
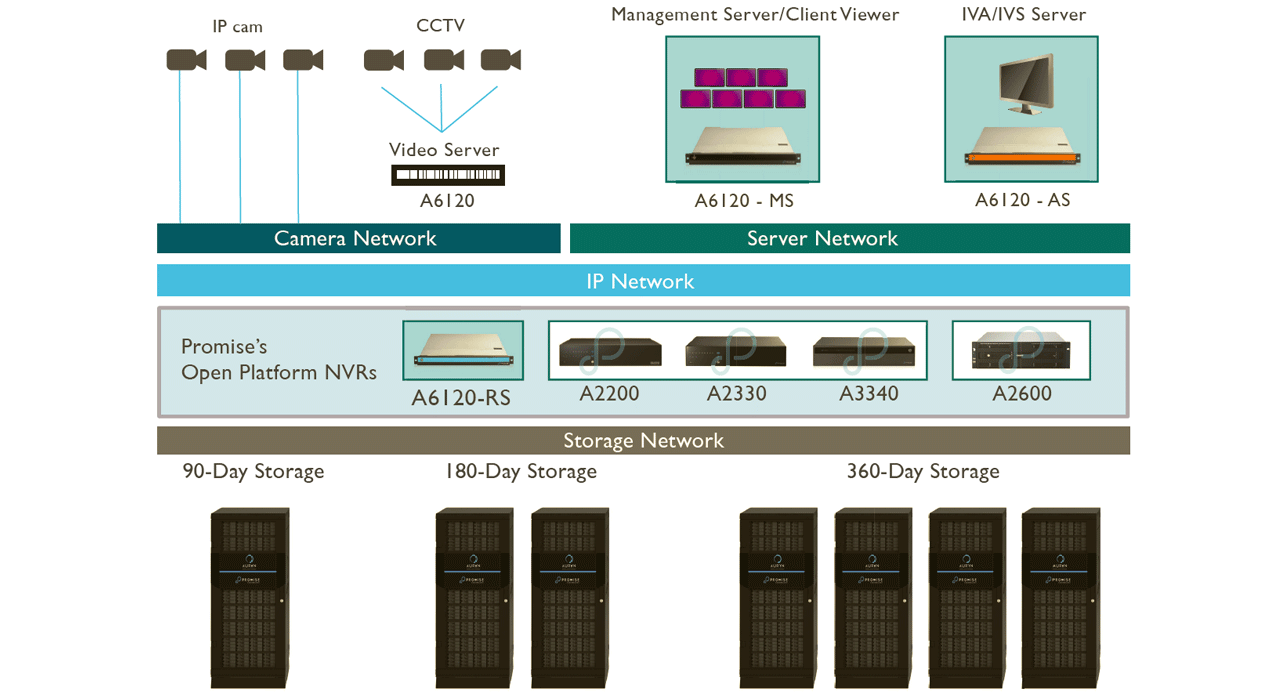
Tymczasem rozpowszechnienie i rozwój cyfrowych systemów monitoringu wideo z wykorzystaniem kamer sieciowych umożliwiło centralne zarządzanie danymi wideo, szybki dostęp do danych wideo oraz analizę obrazów w sposób, który nie był łatwo osiągalny przy użyciu analogowych kamer z przeszłości. Ponadto kamery sieciowe również ewoluowały, umożliwiając rejestrację ostrych, wysokiej rozdzielczości i bardzo czułych obrazów. Są one coraz częściej aktywnie wykorzystywane, nie tylko do rejestrowania nieprzewidzianych okoliczności.
Gdy podczas inspekcji produkcyjnej wykrywane są wady, należy przeprowadzić dochodzenie w celu określenia procesu, w którym wystąpił defekt oraz działań, które należy podjąć. Jednak cofanie przepływu pracy, aby ustalić przyczynę wady, może być niezwykle czasochłonne. W przypadku krytycznych problemów związanych z bezpieczeństwem, należy również rozważyć zatrzymanie linii produkcyjnej do momentu zidentyfikowania przyczyny. Z tego powodu system umożliwiający szybkie i dokładne dochodzenie post-factum jest niezbędny.